Why what you have been taught about DFS is wrong(at least partially)
The student runs the two versions of DFS and he sees that the results are the same so he quickly memorizes the BFS algorithm and the two small differences to transform it into DFS and he lives a happy life with the thought that he basically learned 2 algorithms for the price of one.


"The trouble with the world is not that people know too little, it's that they know so many things that just aren't so." - Mark Twain
Sadly for me (I guess happily for my sanity) sometimes when I read and learn new things I do not fully put them through my thought filter and I just accept them as they are stated. Today I am going to talk about such a case and I hope it will help you remove one of the many misconceptions that we live with.
For some crazy reason, recently I revisited the two well known graph traversal algorithms, Depth-First Search (DFS for short) and Breadth First Search (BFS for short) and came to some conclusions and realizations which apparently were interesting enough to wake me up from my months long hibernation since I last wrote a post.

For the case where the details of the two algorithms are a little bit fuzzy and also to setup the scene for the grand reveal at the end I will go through the process of how usually DFS and BFS are taught (at least in my experience and as far as I see how it is mostly taught on the Internet if you search for these two algorithms). First we need an example graph. We will work with the one shown below:
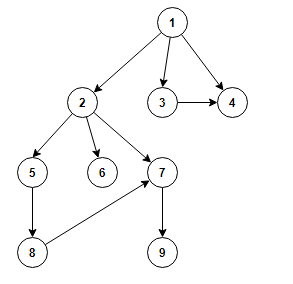
Breadth First Search
BFS starts with a node of the graph which will act as a root node in the context of the algorithm. From the root, it will continue exploring the graph by traversing completely a level at a certain depth before going to the next one. Since we are traversing a graph we have to be careful to not visit the same node twice.
For the example above the traversal order would be:
- Level 0: 1
- Level 1: 2 -> 3 -> 4
- Level 2: 5 -> 6 -> 7
- Level 3: 8 -> 9
The classic implementation of this algorithm is iterative and involves a Queue which will mostly take care for us that the order of traversal is breadth first. A set is used also to keep track of discovered nodes: before adding any node to our queue of nodes to visit, we first check this set if the node was already previously added to the queue. One example of such an implementation is given below:
void breadthFirstTraversal(Node root) {
if (root == null)
return;
//Create and initialize the set which
//will contain discovered nodes
Set<Node> discovered = new HashSet<>();
discovered.add(root);
//Create and initialize queue which
//will contain the nodes left to visit
Deque<Node> queue = new ArrayDeque<>();
queue.offer(root);
while (!queue.isEmpty()) {
Node current = queue.poll();
//visit the node; in this case just print
// the node value
System.out.println(current.getValue());
for (Node child : current.getChildren()) {
//add to the queue any child node of the
//current node that has not already been discovered
//and also add it to the set of
//discovered nodes
if (!discovered.contains(child)) {
queue.offer(child);
discovered.add(child);
}
}
}
}
Depth First Search
Now that we know what BFS is, it should be intuitive how using a DFS traversal style would work. Instead of going level by level, the algorithm will start with a root node and then fully explore one branch of the graph before going to the next one. For our example graph (which I am showing below again so it is easy to follow) the traversal order would be:
- Branch 1: 1 -> 2 -> 5 -> 8 -> 7 > 9
- Branch 2: 6
- Branch 3: 3 -> 4
DFS lends itself quite nicely to a recursive approach so the classic implementation looks something like this.
void depthFirstTraversal(Node root){
if(root == null){
return;
}
//initialize the set which will contain
// our discovered nodes
Set<Node> discovered = new HashSet<>();
//call the recursive function starting
//with the provided root
dfsRecursive(root, discovered);
}
void dfsRecursive(Node current, Set<Node> discovered){
//mark the node as discovered
discovered.add(current);
//visit the node; in this case we just
//print the value of the node
System.out.println(current.getValue());
//recursively call the function on all of
//the children of the current node if
//they have not already been discovered
for(Node child : current.getChildren()){
if(!discovered.contains(child)) {
dfsRecursive(child, discovered);
}
}
}
At this point your teacher will say: "You know what? To help you out to see that these algorithms are not that different, let me show you how to implement DFS iteratively". They will mention that it is almost the same as BFS except two differences:
1. Use a stack instead of a queue.
2. Check if we have visited a node after we pop from the stack. This is opposed to checking before we add a node to the stack as we do in BFS where we check a node before adding it to the queue.
The classic implementation looks something like this (even on Wikipedia it is explained somewhat similarly):
void depthFirstTraversalIterative(Node root){
if (root == null)
return;
//Create the set which
// will contain discovered nodes
Set<Node> discovered = new HashSet<>();
//Create and initialize stack which
// will contain the nodes left to visit
Deque<Node> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
Node current = stack.pop();
if(!discovered.contains(current)){
discovered.add(current);
//visit the node; in this case just print
// the node value
System.out.println(current.getValue());
//add to the stack all the children
//of the current node
for(Node child : current.getChildren()){
stack.push(child);
}
}
}
}
The student runs the two versions of DFS and he sees that the results are the same so he quickly memorizes the BFS algorithm and the two small differences to transform it into DFS and he lives a happy life with the thought that he basically learned 2 algorithms for the price of one. One of such students being me.

Digging deeper
A more inquisitive mind will stop and ask: Wait a minute, where do those two differences between DFS and BFS come from? Good question! Let us explore!
The first one is usually answered with the following: When implementing DFS recursively a stack is used implicitly behind the scene to store the data while visiting the graph so it only makes sense that we explicitly also use a stack for the iterative approach right? Sounds reasonable.
The second difference is not usually discussed though and here things actually get interesting.
First let's ask ourselves why in the BFS implementation we check if the node is visited before we add it to the queue?
To answer that let's see what happens if we check after we poll the node from the queue. We will zoom in at the moment we visit node 3.
Node 4 will in both cases be already in our queue. If we do what we usually do and mark node 4 as discovered before adding it to the queue, then we will have the information that node 4 is already discovered and we would not add it again to the queue. This situation is shown in the picture below.
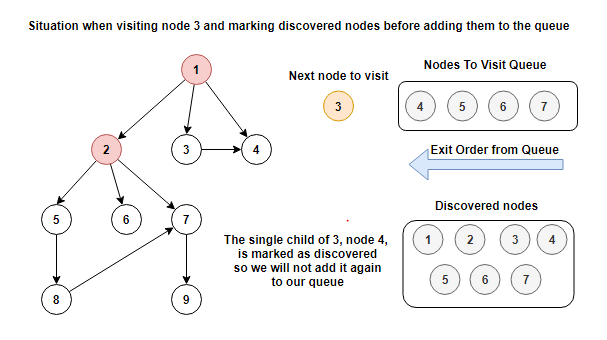
With the change that we made, the discovered nodes set does not have node 4 as a member so we will add it again to the queue. The situation is shown below.
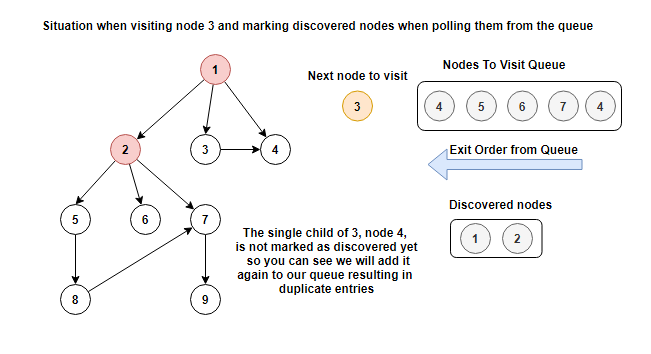
Since the queue is a First In First Out structure, it turns out that from a result perspective this difference does not matter since we will anyway first visit the node that we first added to the queue and we mark it then as discovered. When trying to visit again the same node we will see it as already visited. The main take away is that we want to mark nodes as discovered before adding them to the queue so we do not have duplicates in the queue, this mainly helping with the memory profile of the algorithm since the number of nodes in the queue will be kept to the minimum required.
If we turn our attention to the DFS iterative version we can think that maybe it makes sense also there to do the same thing as in BFS and mark as discovered nodes before we add them to the stack, so let's do it! With this small modification the visiting order of the example graph (again shown below for convenience) will be:
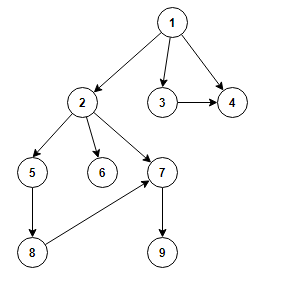
- Branch 1: 1 -> 2 -> 5 -> 8
- Branch 2: 6
- Branch 3: 7 -> 9
- Branch 4: 3
- Branch 5: 4
Wait what? We get different result than in the recursive approach...that cant be right!?
Being misled
So what is happening here? We need to realize that just by using a stack for our iterative implementation because the recursive implementation uses one will not auto-magically make the two behave the same.
If you think a little more in depth about what the recursive version actually does you will notice that, as opposed to the iterative version, we do not save on the implicit stack all the children of the current node, we only save the current node and implicitly we also save on which of the children we will recursively call the algorithm next! For example for the root node we never save anywhere on any stack node 3 and 4, we only get to visit them because this recursive approach implicitly provides us a backtracking mechanism where once a path is completely explored we can go to the next path.
In our iterative approach we save all the children on the stack with the hope that the Last In First Out behavior of the stack will give us the DFS behavior of the recursive implementation. As we saw, this only works when we mark a node as discovered after we pop it from the stack( I will let as an exercise to go through the traversal and understand exactly where the result difference comes from). As in the BFS case that we studied above, this will result in having the same node multiple times in our stack.
So I think here is where people are misled because when we take all into account the situation can be resumed like this:
- When we implement BFS we are being taught that we do not want duplicates in our Queue so we must mark nodes as discovered before adding them.
- When we implement iterative DFS we are being taught to forget about not wanting duplicates in our data structure(this case the stack) because now we just want to mimic the recursive implementation so we will sacrifice our principle from the queue implementation.
The second teaching seems contradictory with the first one. If this is done just to save the students from the extra complexity, then I think that is wrong because the whole purpose of studying these algorithms should be to understand their inherent workings not for people to be able to memorize them more easily.
Because of the differences between the inner workings of the recursive implementation and the classic iterative implementation the two can have vastly different behaviors in terms of memory depending on the graph structure. A prominent case that illustrates this is a star graph: a single central node surrounded by a large number (say, 1000) of child leaf nodes. An example shown below, but with only a couple of nodes.
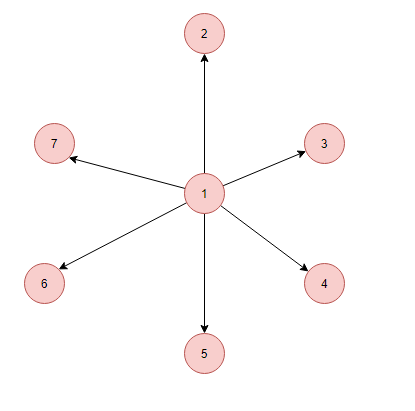
If you run the iterative version of DFS that we saw previously on this graph using the central node as the starting point, the stack size will grow to 1000 since we will be adding all the child nodes to the stack before going to the next iteration. The recursive DFS algorithm will need an implicit stack depth of only 1 to traverse this entire graph. That is 1000 vs 1 in terms of memory requirements!
True DFS
The good news is that once we actually understand what the recursive implementation actually does we can implement an iterative version that indeed has the same behavior, not one that only pretends to do. What we need to do is explicitly code the backtracking behavior of the recursive DFS implementation. We will do this by keeping in the stack info about which child of a node we need to visit, rather then the node itself. The algorithm implementation follows with some inline comments to explain what is happening:
// data structure for storing the required info on the stack
class TraversalInfo{
Node parent;
int childPos;
public TraversalInfo(Node parent, int childPos) {
this.parent = parent;
this.childPos = childPos;
}
public Node getParent() {
return parent;
}
public int getChildPos() {
return childPos;
}
public void setChildPos(int childPos) {
this.childPos = childPos;
}
}
void trueDepthFirstTraversalIterative(Node root){
//as always create and initialize
//the set of discovered nodes
Set<Node> discovered = new HashSet<>();
discovered.add(root);
//create and initialize the stack which will
//indicate which node to visit next. You can
//observer that we are not saving anymore directly
//what node to visit next, but a parent node and
//the index of its child that we should visit next
Deque<TraversalInfo> stack = new ArrayDeque<>();
stack.push(new TraversalInfo(root, 0));
//we visit the root node before going
//into our loop
System.out.println(root.getValue());
while (!stack.isEmpty()) {
TraversalInfo current = stack.pop();
Node currentParent = current.getParent();
int currentChildPos = current.getChildPos();
//we check if there are more child nodes
if(currentChildPos < currentParent.getChildren().size()){
Node child = currentParent.getChildren().get(currentChildPos);
//we save in the stack the next child index
//together with its parent
current.setChildPos(currentChildPos + 1);
stack.push(current);
//check if current child discovered already
if(!discovered.contains(child)){
//add it to the set of discovered nodes
discovered.add(child);
//visit the child; in this case just print out its value
System.out.println(child);
//add to the stack the info for visiting its child nodes
//starting from the first one
stack.push(new TraversalInfo(child, 0));
}
}
}
}
As we can see this implementation is a little more complex than the one we are used to. Here we use an extra data structure to keep the required info, but there is an alternative implementation using an extra stack which I will leave as an exercise for anyone curious enough to try it out.
In some circles this iterative implementation and the recursive one are called True DFS, while the iterative one that we saw in the beggining is called a pseudo DFS traversal since at the surface level it mimics the True DFS algorithm, but if you look at its inner workings it does not.

Closing remarks
Let me know in the comments for how many of you this was obvious from the start and how many actually lived with the iterative DFS implementation without questioning it.
Also let me know of any other simmilar example that you may have.
If you like the content do not forget to subscribe!




Member Discussion